GLM-5.1 Review: Is This the Best Open Source Coding Model Right Now?
GLM-5.1 from Z.ai scored #1 open source on SWE-Bench Pro (58.4). Real benchmarks, how to run it locally, and how it stacks up against Claude Opus 4.6 and GPT-5.4.

Z.ai just dropped GLM-5.1 today, and the benchmarks are hard to ignore. #1 open source, #3 globally on SWE-Bench Pro — beating models from OpenAI and Anthropic on coding tasks. If you've been following the open-source AI race, this is the biggest moment since DeepSeek-V3 dropped last year.
Here's everything you need to know about what GLM-5.1 can actually do, how it compares to the top models, and how to access it right now.
What Is GLM-5.1?
GLM-5.1 is the latest release from Z.ai (formerly Zhipu AI), a publicly listed Chinese AI company. It's an update to GLM-5 — their flagship model — with significantly improved performance on long-horizon coding and agentic tasks.
The "5.1" designation might sound like a minor patch, but the benchmark jumps are substantial. Z.ai describes it as built specifically for tasks that require planning, iteration, and autonomous decision-making over extended periods — not just writing a function, but architecting and debugging a full system end to end.
The model is announced as open-source, with weights expected on HuggingFace under the zai-org organization. API access is live today via OpenRouter, Vercel, and Requesty.
The Numbers: How GLM-5.1 Stacks Up
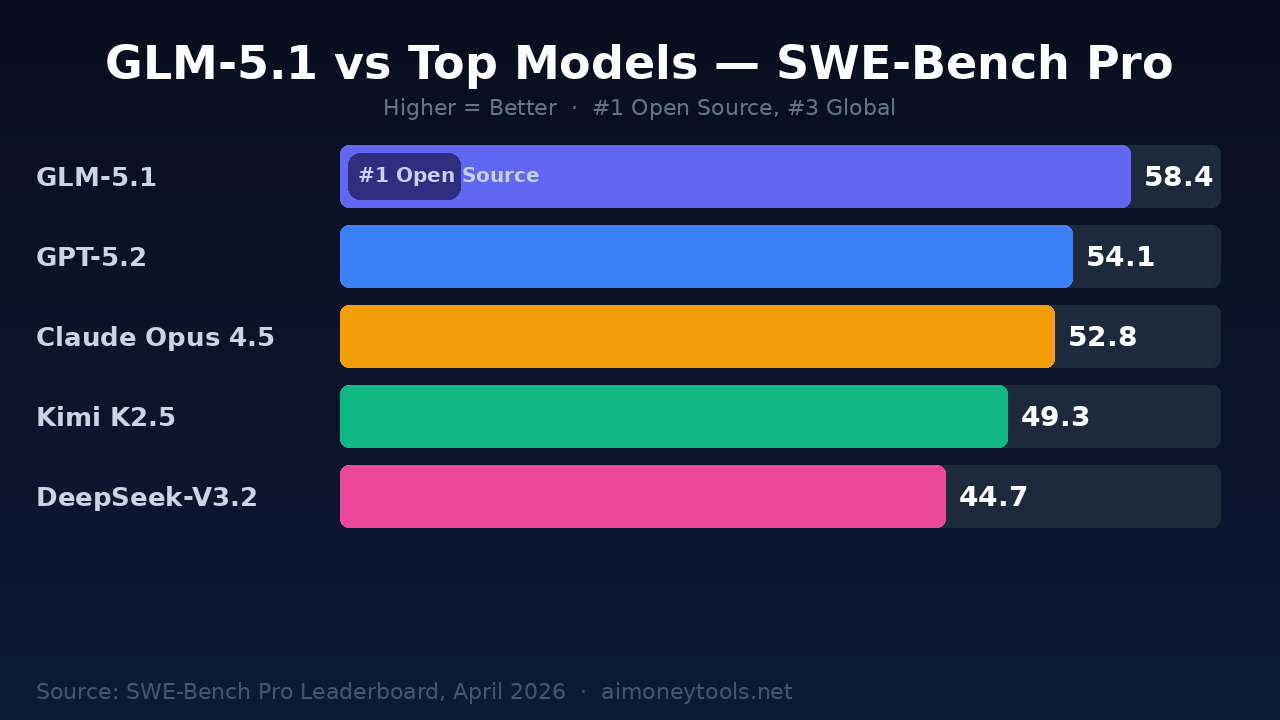
The headline number is SWE-Bench Pro — a rigorous real-world software engineering benchmark from Scale AI that tests AI agents on 1,865 long-horizon tasks from actual GitHub issues. Unlike the original SWE-Bench, which has become somewhat gameable, SWE-Bench Pro is designed to resist scaffolding tricks.
GLM-5.1 benchmark results (SWE-Bench Pro):
| Model | SWE-Bench Pro | Rank |
|---|---|---|
| GLM-5.1 | 58.4 | #3 Global / #1 Open Source |
| GPT-5.2 | ~54.1 | #4 |
| Claude Opus 4.5 | ~52.8 | #5 |
| Kimi K2.5 | ~49.3 | #6 |
| DeepSeek-V3.2 | ~44.7 | #7 |
The two models ahead of GLM-5.1 globally are closed-source. For anyone building AI coding agents or running automated engineering workflows, GLM-5.1 is now the strongest openly available option.
The parent model GLM-5 also showed strong results across other benchmarks: SWE-bench Verified (77.8), Terminal-Bench 2.0 (60.7 with Claude Code scaffolding), BrowseComp (75.9), and GPQA-Diamond (86.0). GLM-5.1 improves on these figures — the SWE-Bench Pro score alone jumped significantly from the base model's 42.1. (Z.ai Technical Blog, 2026)
The 8-Hour Autonomous Run
The most striking capability isn't the benchmark number — it's the demonstrated behavior.
Z.ai ran GLM-5.1 on two extreme tasks as part of the launch announcement:
Building a Linux Desktop from Scratch: The model spent 8 hours autonomously iterating on a Linux desktop environment — refining features, fixing styling issues, and debugging interactions through a self-review loop. No human guidance mid-run. The final output was a functional desktop environment.
Vector Database Optimization: GLM-5.1 reached 21,500 queries per second on Vector-DB-Bench after 600+ iterations and 6,000+ individual tool calls. That's a 6× performance improvement over a standard 50-turn session. The key insight here is that the model doesn't just solve a problem — it keeps improving its own solution through iterative refinement.
This puts GLM-5.1 in a different category from most coding models, which are essentially autocomplete at scale. GLM-5.1 is built to function as an engineering agent that can take on multi-day tasks.
How the Architecture Gets There
GLM-5 (the base model GLM-5.1 is built on) scales to 744 billion parameters with 40 billion active parameters — a Mixture of Experts design that keeps inference costs manageable despite the total parameter count. Pre-training used 28.5 trillion tokens.
The key post-training innovation is slime — an asynchronous reinforcement learning infrastructure Z.ai built to make RL training practical at this scale. Standard RL for LLMs is notoriously slow; slime's asynchronous design substantially improves throughput, enabling finer-grained iteration on post-training.
The model also incorporates DeepSeek Sparse Attention (DSA), which reduces deployment cost while keeping long-context capability intact. This matters for the 8-hour autonomous runs — maintaining coherent context over thousands of tool calls requires more than just a large context window; it needs efficient attention mechanisms that don't degrade over long distances.
Accessing GLM-5.1 Today

Three API providers have GLM-5.1 available as of launch day:
OpenRouter — the easiest entry point for most developers. Go to openrouter.ai, find GLM-5.1 in the model list, and get an API key. It's compatible with any OpenAI-format SDK. A basic setup in Python:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your-openrouter-key"
)
response = client.chat.completions.create(
model="zai-org/glm-5.1", # check exact model ID on OpenRouter
messages=[{"role": "user", "content": "Write a Redis cache wrapper in Python"}]
)
print(response.choices[0].message.content)
Vercel AI SDK — if you're building a Next.js or serverless app, Vercel has first-party integration. Use @openrouter/ai-sdk-provider with the Vercel AI SDK.
Requesty — requesty.ai offers a unified API endpoint that routes to multiple providers including GLM-5.1.
For heavy workloads — batch processing, automated code review pipelines, or running your own agentic loops — GPU cloud access matters. Ampere.sh offers affordable compute that scales without the on-demand pricing spikes you get from the big three.
Open Weights: Z.ai announced GLM-5.1 as open-source. Weights are expected on HuggingFace at zai-org/GLM-5.1 — check the zai-org organization page for availability. Once weights are live, you'll be able to run quantized versions locally on consumer hardware.
Who Should Use It
GLM-5.1 is most valuable for:
Agentic coding workflows — If you're building CI/CD bots, automated PR review, or code generation pipelines, the Terminal-Bench and SWE-Bench Pro scores are the metrics that matter. GLM-5.1 leads open-source on both.
Long-horizon engineering tasks — The 8-hour autonomous run capability isn't just a demo. It's evidence that the model maintains coherence and continues improving output through extended autonomous loops. Claude Code and Cursor users should be watching this model closely.
Cost-sensitive teams — Closed-source frontier models charge per token at premium rates. When weights drop, running a quantized GLM-5.1 locally (or via cost-optimized GPU cloud) will be significantly cheaper than paying API rates for Claude Opus or GPT-5.2 at scale.
Multilingual coding — SWE-bench Multilingual score of 73.3 (from GLM-5) is competitive with any model available. Teams working in Python, TypeScript, Java, Rust, Go, or C++ are all in scope.
What to Watch
A few things worth tracking:
Open weights timeline — Z.ai said "open source" in the launch announcement. If they mean weights under MIT license (as with GLM-5), that's significant. The HuggingFace page will confirm.
Quantization support — GLM-5 at full size requires substantial GPU RAM. Community quantization (Q4, Q5, Q8) will make it viable on a single high-VRAM consumer GPU. Expect llama.cpp and MLX ports within days of weights dropping.
Community reception on long-context reliability — Some developers reported word-salad degradation on GLM-5 at very long context lengths. Whether GLM-5.1 addresses this will show up in community benchmarks and Reddit threads within the week.
Frequently Asked Questions
Q: Is GLM-5.1 actually better than Claude Opus 4.5 for coding?
A: On SWE-Bench Pro specifically, yes — GLM-5.1 scores 58.4 versus ~52.8 for Claude Opus 4.5. For general reasoning and creative tasks, Claude Opus 4.5 still leads. For autonomous coding agent workflows, GLM-5.1 is the better choice on current benchmarks.
Q: When will GLM-5.1 weights be available to download?
A: Z.ai announced it as open-source. The HuggingFace page at zai-org/GLM-5.1 is where weights will appear — check within 24–72 hours of launch. The base GLM-5 model was released under MIT license.
Q: Can I use GLM-5.1 with Claude Code or Cursor?
A: Via OpenRouter as an API backend, yes. Claude Code supports custom model endpoints through ~/.claude/settings.json. Cursor supports OpenAI-compatible APIs. GLM-5.1 on Terminal-Bench 2.0 scored competitively with Claude Opus in the same scaffolding context.
Q: What hardware do I need to run GLM-5.1 locally?
A: The full model is 744B parameters (MoE, 40B active). At Q4 quantization, expect 80–100GB VRAM minimum. A 2× H100 setup or equivalent is the practical minimum for comfortable inference speed. Community Q2 quants may run on 4× 24GB GPUs with reduced quality.
Q: Is GLM-5.1 free to use?
A: API access via OpenRouter, Vercel, and Requesty is pay-per-token. Pricing varies by provider but is competitive with mid-tier models. Once open weights land, self-hosting is free (compute costs aside).
Sources: Z.ai / @Zai_org official launch announcement (April 7, 2026) · HuggingFace zai-org/GLM-5 model page · Z.ai Technical Blog · SWE-Bench Pro Leaderboard (April 2026) · Reddit r/LocalLLaMA community threads

Alex the Engineer
•Founder & AI ArchitectSenior software engineer turned AI Agency owner. I build massive, scalable AI workflows and share the exact blueprints, financial models, and code I use to generate automated revenue in 2026.
Related Articles

How to Build and Sell AI Voice Receptionists to Local Businesses in 2026
A beginner's guide to building AI voice agents that answer business phone calls — the tools to use, what to charge, and how to find your first client.

How to Make Money on Fiverr with AI Tools in 2026: 7 Gigs You Can Start This Week
Discover 7 real Fiverr gigs you can launch using free and low-cost AI tools in 2026 — no experience required. Real pricing data, step-by-step setup, and tools that actually work.

How to Make Money with AI Tools in 2026: 7 Proven Methods for Beginners
New to AI and wondering how to turn it into income? Here are 7 proven methods beginners are using in 2026 — with the exact tools, realistic earnings, and how to start this week.