DeepSeek V4: Release Date, Features, and What to Expect
DeepSeek V4 is targeting late April 2026. Here's everything confirmed about its 1 trillion parameter MoE architecture, Huawei chip strategy, context window, and how it stacks up against Claude Mythos and GPT-5.4.

DeepSeek has rattled the AI industry before. Its R1 model landed in early 2025 and sent NVIDIA's stock into freefall. DeepSeek V3 topped the OpenRouter leaderboard and is still the most popular paid API model as of April 2026.
V4 is next — and everything reported so far suggests it will be bigger.
DeepSeek's founder, Liang Wenfeng, confirmed in an internal communication on April 10, 2026 that V4 is targeting a late April 2026 launch. That's the clearest signal yet after two previous delays (originally February, then mid-April). Infrastructure tests are already running — V4-Lite has been live on select API nodes since early April, which typically means the full model is close.
Here's everything currently known about DeepSeek V4, broken down by what's confirmed, what's credible, and what's still speculation.
DeepSeek V4 Release Date
Target: Late April 2026
The April 10 signal from founder Liang Wenfeng is the strongest public confirmation yet. Previously:
- February 2026 — Original target window. Missed.
- Mid-April 2026 — Second reported window. Quietly slipped.
- Late April 2026 — Current target, confirmed internally.
One detail that has gained traction in the r/DeepSeek community: DeepSeek historically launches on Mondays, Wednesdays, or Thursdays. That puts the most likely release days at April 20, 22, 23, 27, or 29. The April 20 date is particularly notable — it coincides with Huawei's scheduled product announcements for 2026, and DeepSeek V4 is closely tied to Huawei's Ascend chip rollout.
V4-Lite (a smaller variant) has been visible on some API infrastructure since early April. That kind of staged infrastructure testing almost always precedes a full launch within weeks.
DeepSeek V4 Architecture: 1 Trillion Parameters, Mixture of Experts
V4 is reported to use a Mixture-of-Experts (MoE) architecture with:
- ~1 trillion total parameters — the largest reported DeepSeek model to date
- 32–37 billion active parameters per token — only a fraction of the total activates for any given task
This isn't as wild as it sounds. DeepSeek V3 used the same approach (671 billion total, smaller active slice), and it's exactly why V3's pricing was so aggressive while still delivering competitive performance. MoE lets you scale total model capacity without proportionally scaling inference cost.
For end users, this means V4 should be significantly more capable than V3 — in reasoning, long-context tasks, and coding — while remaining relatively cheap to call via API.
DeepSeek also published research on Engram in January 2026 — a conditional memory system designed for long-context retrieval inside large MoE models. V4-Lite is already showing dramatically improved context recall in early API testing, which suggests Engram is being integrated into the full V4 architecture.
The 1 Million Token Context Window
The most-discussed V4 spec: 1 million token context window.
This comes from leaks, community analysis of API node behavior, and DeepSeek's published Engram research — not an official spec sheet. DeepSeek hasn't published V4 documentation yet. The API still shows V3.2 as the production model.
That said, the technical foundation for it is visible. Engram was built specifically to handle long-context retrieval at scale, and V4-Lite is already demonstrating extended recall that V3 couldn't reliably do.
For practical comparison:
- DeepSeek V3 — 128K context
- Gemma 4 E4B — 128K context
- GPT-5.4 — 256K context
- Claude Mythos — reported multi-million token context (not publicly confirmed)
- DeepSeek V4 (reported) — ~1 million tokens
If confirmed, 1M context at DeepSeek pricing would be a significant capability edge for long-document analysis, codebase review, and research workflows.
The Huawei Angle: The Most Important Story Nobody Is Talking About
Reuters confirmed in April 2026: DeepSeek V4 will run on Huawei Ascend chips.
Not NVIDIA H100s. Not AMD MI300s. Huawei Ascend processors — China's domestic GPU alternative.
More notably: DeepSeek reportedly gave Huawei and other Chinese chipmakers early optimization access while deliberately denying that window to NVIDIA and AMD. That's a deliberate strategic positioning, not just a supply-chain workaround.
The context matters. US export controls have been restricting Chinese companies from purchasing the most advanced NVIDIA hardware. The argument from Washington has been that these restrictions slow Chinese AI development. DeepSeek V4 being trained and optimized on Huawei chips — and potentially performing at frontier level — would be a direct empirical counter-argument.
If V4's benchmarks hold up under independent testing, the implications go well beyond DeepSeek's API pricing. It would validate Huawei's Ascend platform as a credible alternative to NVIDIA in the frontier AI training stack, at a geopolitical moment when that question matters enormously.
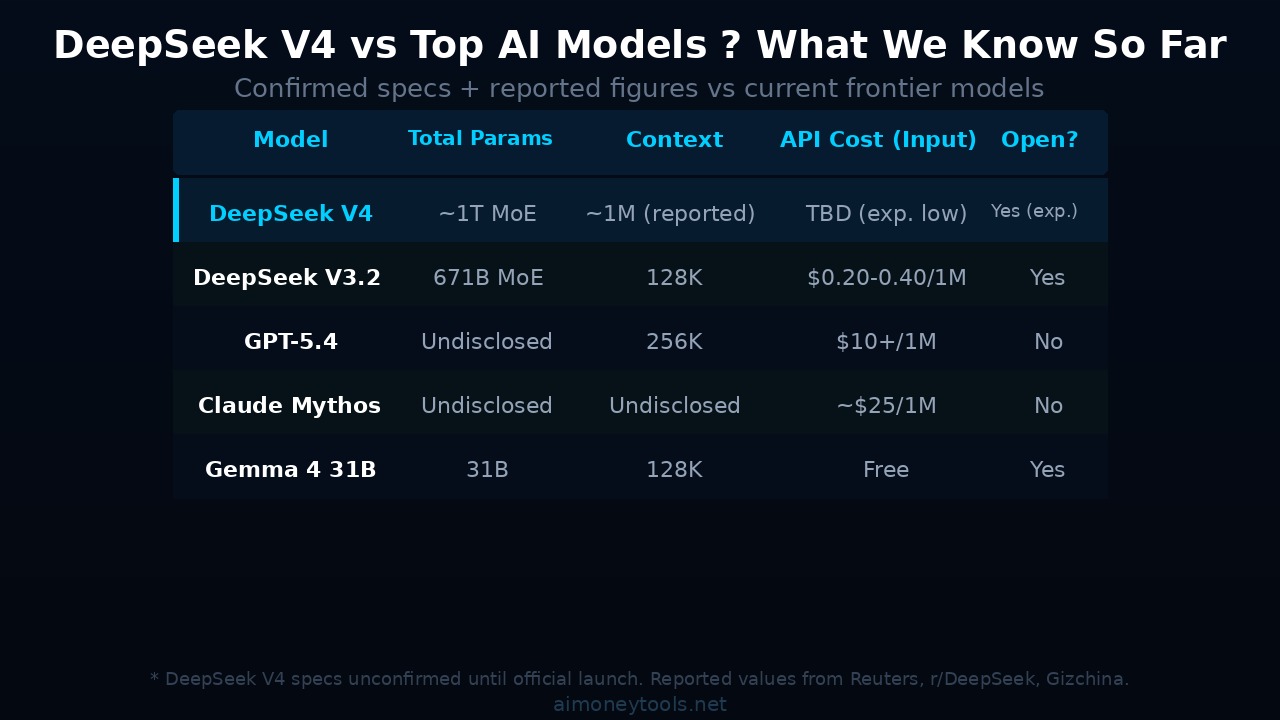
DeepSeek V4 vs. Current Models
Here's how V4 is expected to stack up based on current reporting:
| Model | Total Params | Active Params | Context | API Cost (Input) | Available |
|---|---|---|---|---|---|
| DeepSeek V4 | ~1T (MoE) | ~32-37B | ~1M (reported) | TBD (likely cheap) | Late April 2026 |
| DeepSeek V3.2 | 671B (MoE) | ~37B | 128K | $0.20–0.40/1M | Live |
| GPT-5.4 | Undisclosed | Undisclosed | 256K | $10+/1M | Live |
| Claude Mythos | Undisclosed | Undisclosed | Undisclosed | ~$25/1M input | Restricted |
| Gemma 4 31B | 31B | 31B | 128K | Free (open) | Live |
The pricing comparison is where DeepSeek consistently wins. Claude Mythos reportedly costs $25 per million input tokens and $125 per million output tokens. DeepSeek V3.2 costs around $0.20–0.40 per million. Even if V4 is significantly more expensive than V3.2, it's likely to be a fraction of Mythos pricing.
That's the core DeepSeek value proposition: frontier-adjacent performance at 10–100x lower API cost.
DeepSeek V4: Multimodal?
Multiple sources report V4 will include multimodal capabilities — handling image input alongside text. DeepSeek already released Janus (an image understanding and generation model) and has published multimodal research throughout 2025.
Whether V4 integrates vision natively into the main model or ships as a separate multimodal variant (like Gemini or GPT-4o's architecture) isn't confirmed. Earlier reports suggested a unified multimodal architecture, but this hasn't been officially confirmed.
What's worth watching: DeepSeek's multimodal models have historically outperformed expectations on visual benchmarks. If V4 includes strong vision capabilities at V3-level pricing, it changes the economics of vision API calls significantly.
How to Access DeepSeek V4 When It Launches
DeepSeek historically releases new models in two ways:
- DeepSeek.com — direct chat interface, available globally
- DeepSeek API — pay-per-token access, extremely competitive pricing
- Open weights on Hugging Face — usually follows the API launch by a few weeks
If you want to run V4 locally when it drops, you'll need serious GPU compute. V4 at 1 trillion total parameters is not a consumer-GPU-at-home model. Even with MoE efficiency, you're looking at multi-GPU setups for anything approaching fast inference.
For cloud-based API access, DeepSeek's own API will be the fastest and cheapest option at launch. If you need to run it programmatically or integrate it into pipelines, Ampere provides GPU cloud access that works well for running open-weight models through Ollama or vLLM once DeepSeek publishes the weights.
For building AI-powered applications on top of DeepSeek V4's API once it launches — whether that's chatbots, automation workflows, or custom tools — CustomGPT is worth looking at for no-code deployment if you don't want to write your own API wrappers.
What Could Go Wrong
DeepSeek V4 has already missed two launch windows. A few scenarios to watch:
Export controls tighten. If new US restrictions hit Huawei's Ascend chip production before V4 is fully deployed, the timeline could slip again. V4's entire infrastructure bet is on Huawei.
Benchmark disappointment. The AI community expectations are high. If V4 doesn't meaningfully beat V3.2 on reasoning and coding (especially given Claude Mythos and GPT-5.4 as comparators), community reception will be negative.
Weights delayed. It's possible V4 launches API-first with the open weights following later (or not at all on this scale). DeepSeek has been more open than US frontier labs, but a 1T parameter model is a different commitment to publish openly.
Performance at scale. V4-Lite running well on API nodes is not the same as the full model running at production scale under heavy load. Early launch days for DeepSeek have historically been rough on availability.
Frequently Asked Questions
When exactly will DeepSeek V4 launch? Late April 2026 is the current confirmed target from founder Liang Wenfeng (April 10, 2026). Most likely dates based on DeepSeek's historical launch pattern (Mon/Wed/Thu): April 20, 22, 23, 27, or 29. April 20 is the most-discussed specific date, coinciding with Huawei's product announcements.
What are DeepSeek V4's confirmed specs? Confirmed: MoE architecture with ~1 trillion total parameters and ~32–37 billion active per token; runs on Huawei Ascend chips; targeting late April 2026 launch. Widely reported but unconfirmed: 1 million token context window, multimodal capability.
Will DeepSeek V4 be available to run locally? Open weights are expected but not guaranteed at launch. Given V4's scale (1T total parameters), local deployment requires serious multi-GPU hardware. For most users, API access will be the practical path.
How does DeepSeek V4 compare to Claude Mythos? Different positioning. Mythos is a restricted frontier model at $25/1M input token pricing with no open weights. V4 is being built as a high-capability, low-cost open model. They serve different use cases — Mythos for enterprise security/reasoning at any cost, V4 for developers and teams who need strong performance without the API bill.
Is the 1 million token context window confirmed? Not officially. It's credible based on DeepSeek's Engram research and V4-Lite API behavior, but DeepSeek has not published official V4 documentation. Treat it as a strong rumor until confirmed.
Will DeepSeek V4 really run on Huawei chips? Yes — Reuters confirmed this in April 2026. DeepSeek deliberately gave Huawei early optimization access. This is as much a geopolitical statement as a technical one, given US export control restrictions on NVIDIA hardware.
What happened to the February and mid-April launch targets? Both slipped without public explanation. The pattern appears to be infrastructure readiness — DeepSeek tends to launch when their API infrastructure passes internal stress tests, not on a fixed calendar. V4-Lite being live on API nodes since early April suggests the full model is closer than it was at the last deadline.
DeepSeek has surprised the market every time it's shipped. V3 was supposed to be "good but not frontier." It ended up topping usage charts and forcing pricing adjustments from every major US AI lab.
V4 arrives in a different environment — Claude Mythos is live, GPT-5.4 is deployed, the bar has moved. But DeepSeek's structural advantage has never been about raw benchmarks. It's about delivering 80% of frontier capability at 5% of frontier cost, on open weights, with no usage restrictions.
If V4 lands on schedule in late April, the market response should be immediate. Watch the OpenRouter rankings on launch day.


Alex the Engineer
•Founder & AI ArchitectSenior software engineer turned AI Agency owner. I build massive, scalable AI workflows and share the exact blueprints, financial models, and code I use to generate automated revenue in 2026.
Related Articles

How to Build and Sell AI Voice Receptionists to Local Businesses in 2026
A beginner's guide to building AI voice agents that answer business phone calls — the tools to use, what to charge, and how to find your first client.

How to Make Money on Fiverr with AI Tools in 2026: 7 Gigs You Can Start This Week
Discover 7 real Fiverr gigs you can launch using free and low-cost AI tools in 2026 — no experience required. Real pricing data, step-by-step setup, and tools that actually work.

How to Make Money with AI Tools in 2026: 7 Proven Methods for Beginners
New to AI and wondering how to turn it into income? Here are 7 proven methods beginners are using in 2026 — with the exact tools, realistic earnings, and how to start this week.